The human-in-the-loop (HITL) process in agentic AI
With the idea of "Agentic AI" becoming more prevalent in the generative AI (GenAI) space, it also becomes more important that we're able to put controls in place to allow for a human-in-the-loop process, like to approve or deny an agent's planned action. While it may not be too consequential to omit this process from actions that are non-destructive, such as retrieving the weather or reading from a database, it's definitely not ideal to omit it for actions that modify the environment, like executing code or sending e-mails.
For example, Claude Code, by default, waits for user approval before it executes commands or modifies your source code, showing the edits it plans to apply.
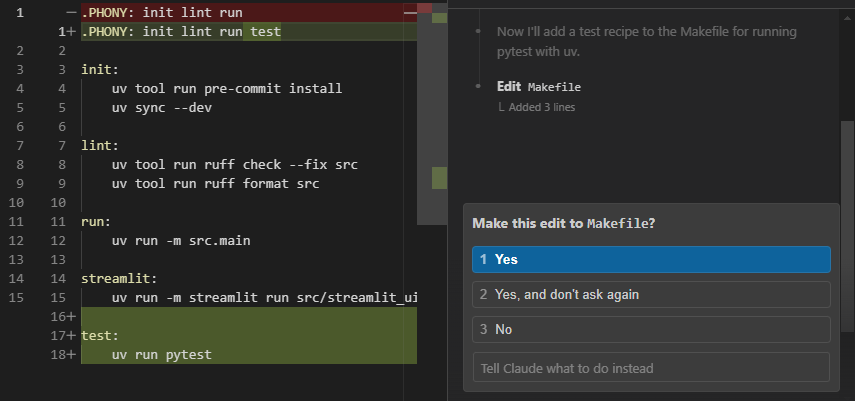
Additionally, OpenAI's recently released AgentKit's Agent Builder also has a node for quickly integrating user approval into your agentic workflow.
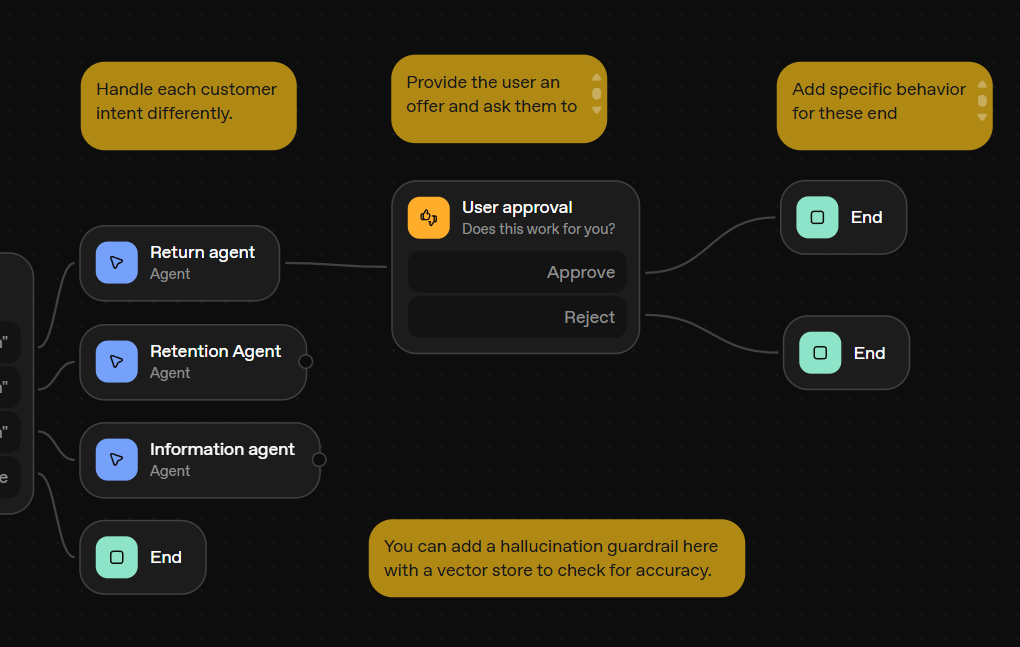
In this post, I'll show you how I implemented human-in-the-loop in my Learn with GenAI side project using LangGraph in a stateless backend REST API.
Context: What "Learn with GenAI" is and why I needed to have a human-in-the-loop process
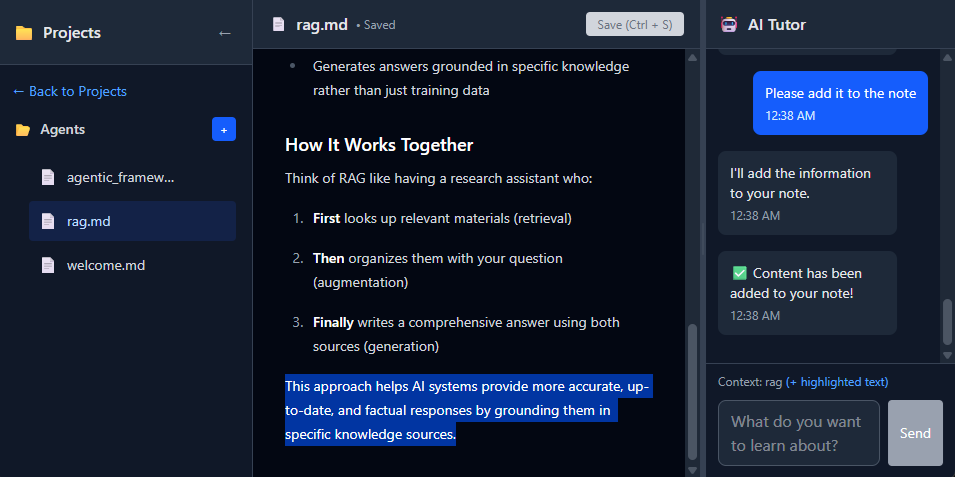
One of my primary personal use cases for GenAI is using it to learn things efficiently. If there was a concept I didn't fully grasp, I could ask the AI to walk me through an explanation and answer my questions to fill in the knowledge gaps. This has been especially useful, for example, for my Japanese language learning. I'd give it a Japanese sentence whose meaning I don't fully understand, and I'd instruct it to break down the sentence phrase-by-phrase, explain to me their semantic roles, and tell me why one grammar point was used over another.
As a side project, I wanted to create a tool that was like Cursor but specifically for learning and note-taking. This is the goal of Learn with GenAI. You'd have a note editor in the middle, and you can ask questions to an AI assistant (a.k.a. AI tutor) in a sidebar about the concepts you're learning or the things you've written down in your notes.
Additionally, part of the feature set I wanted to include in this project was to allow the user to ask the AI assistant to summarize the discussion they've had so far and directly add the content to the currently active note. However, I realized, similar to Cursor or Claude Code, that if the AI assistant is able to add content to a note directly without asking for the user's consent immediately prior (even if the user might have asked for it in a previous message), that behavior could easily break the user's trust and sense of control. In this case, you want the user to be able to see the content the AI assistant generated, have the user approve or reject that content, and only then add the approved content to the note.
How the "Learn with GenAI" system is set up
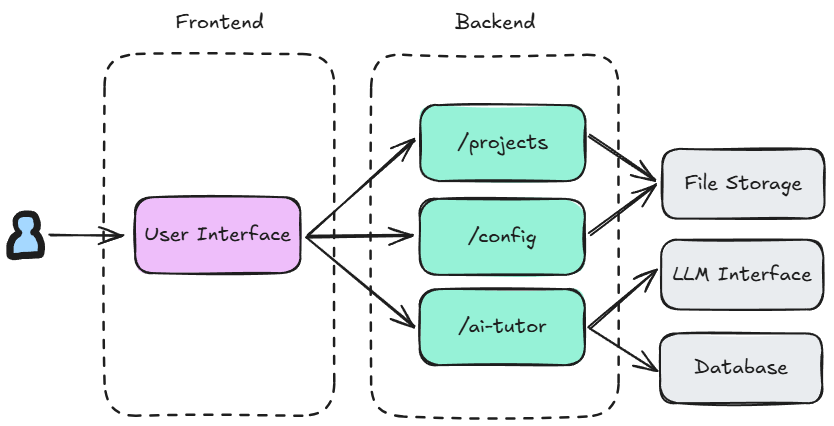
The Learn with GenAI repository contains both the frontend (implemented with Next.js) and the backend (a REST API implemented with FastAPI) code.
Note: It's still a work-in-progress, however, so as of writing, there are still some local-first implementations that will need to be refactored if this were ever to be used in a deployed environment; e.g. the file storage and database (/.db SQLite files) are by default just in a .gitignore'd /data folder in the repository.
The backend was implemented to be stateless, and serves several different routes, including a router for managing projects and files (/projects), another for managing user config (/config), and one for calling functionality related to the AI assistant (/ai-tutor). These different routes are called by the frontend accordingly based on user interaction.
The main endpoint we'll be looking at in this post is the chat endpoint (/ai-tutor/chat). This is the one that handles user input from the AI assistant sidebar and returns one or more responses in a stream depending on the AI assistant's decisions, currently determined by the following state graph.
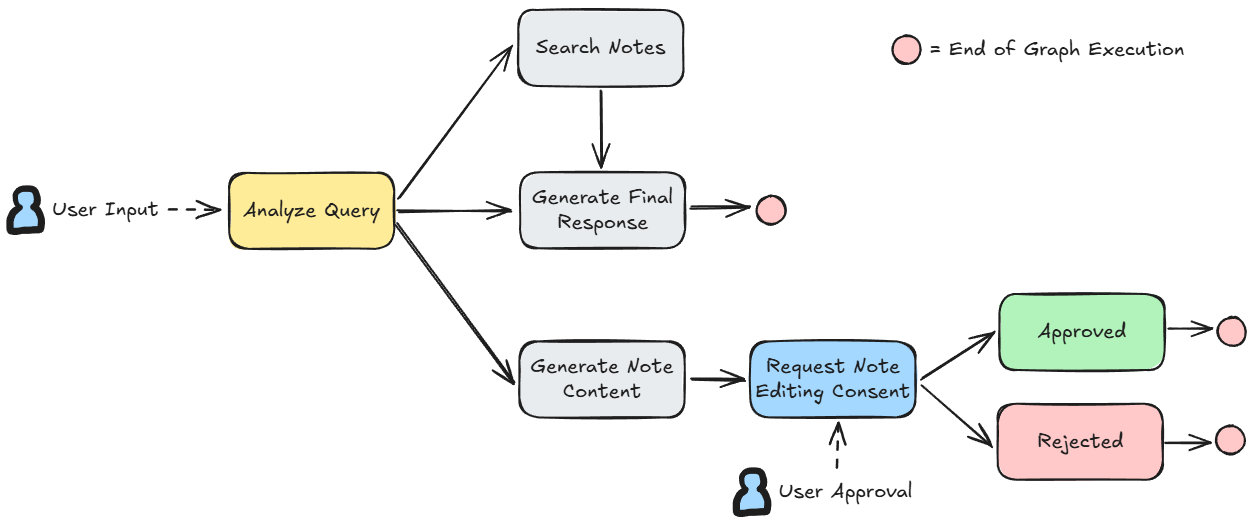
Each node in this state graph is an individual function that takes in the current state and returns changes to that state.
When a user message comes in, the system calls the logic function that builds the graph, initializes state, and executes the graph node by node through a graph.astream loop, yielding output messages (as a streaming response in the endpoint) from each node in the graph it goes through and associating each message with a type to let the frontend know how to handle it.
async for step_result in graph.astream(graph_input, config): ... step_state = list(step_result.values())[0] if "output_messages" in step_state: for output_message in step_state["output_messages"]: yield { "type": output_message["type"], "content": output_message["content"], }
graph.astream's for loop for yielding output messages (/backend/src/logic/ai_tutor/graphs/main.py)For example, in the first node "Analyze Query", it determines what course of action to take depending on the user message. Based on the its decision, it yields the a corresponding "type": "step" message.
response = (await llm.ainvoke(messages)).content.strip() query_type = json.loads(response).get("query_type") if query_type == "SEARCH": return { "output_messages": [ {"type": "step", "content": "Searching your project files..."} ] } elif query_type == "ADD_TO_NOTE": return { "output_messages": [ {"type": "step", "content": "Let me generate some information for your note..."} ] } else: return { "output_messages": [ {"type": "step", "content": "Let me think about that for a bit."} ] }
/backend/src/logic/ai_tutor/nodes/analysis/query_analysis.py)The frontend then receives this message as part of the streaming response from the /chat endpoint as follows.
data: {"type":"step","content":"Searching your project files...","timestamp":"2025-10-12T13:22:53.834210","thread_id":"5efb29e2-8f28-44d9-9fe3-16386bb44e92"}
data:It parses this line, received as plain text, and handles it accordingly based on the "type".
const lines = messageChunk.split("\n"); for (const line of lines) { if (line.startsWith("data: ")) { const data = JSON.parse(line.slice(6)); if (data.type == "step") { // Other conditions also exist for other message types const aiMessage: Message = { id: `${Date.now()}-${Math.random()}`, type: "assistant", content: data.content, timestamp: new Date(), thread_id: data.thread_id, }; setMessages((prev) => [...prev, aiMessage]); } ...
/frontend/src/components/AIAssistant.tsx)It then shows up in the UI as an individual AI tutor message.
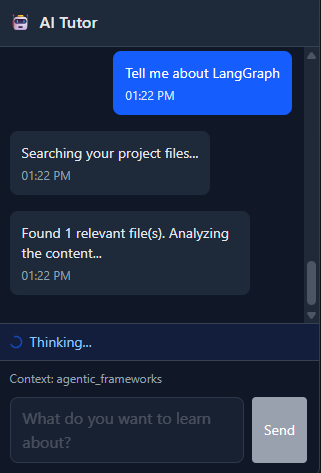
step messages as a representation of the AI tutor's chain-of-thoughtAnother message type, for example, is "final". This is treated similarly to "step" except that the frontend now knows that it's the final message of the current chain of messages the AI assistant is sending and will thus go ahead and remove the "Thinking" UI indicator.
if (data.type === "final") { setIsThinking(false); }
/frontend/src/components/AIAssistant.tsx)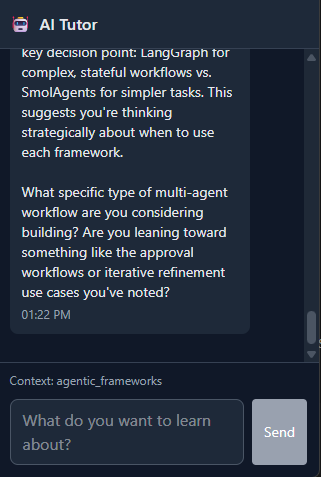
final message has been sent from the backend.The two other notable types are note and content, both of which are part of the human-in-the-loop implementation which I'll discuss next.
How I implemented human-in-the-loop with LangGraph in the stateless backend REST API
Say the user just asked the AI tutor a question about what retrieval-augmented generation (RAG) is, and they had a discussion that helped the user understand the concept. When the user now sends the message, "Can you summarize our discussion and put it in my note?", I want the system to behave as follows:
- The AI assistant first goes through the state graph and, based on the user's message, selects the "Generate Note Content" branch.
- It writes out the content it plans to add to the note.
- It momentarily pauses graph execution to ask the user for approval of the generated content.
- Based on the user's response, it should then either write the content to the note or tell the user that the note generation has been cancelled.
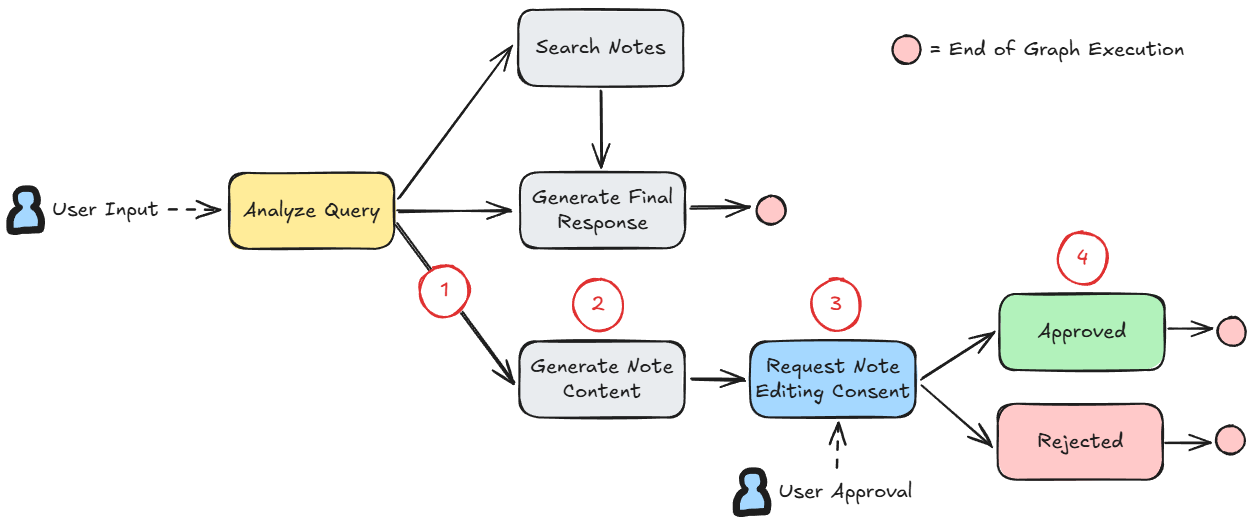
Implementation-wise, in step 3, pausing graph execution to get user input for approval from the frontend means the system needs to do two REST API calls: one for the initial trigger to write the note content and another to resume the graph execution after the user gives their approval (or non-approval). Thus, the AI assistant should somehow be able to recognize that the second API call is connected to the first. However, because the backend API should be stateless, I needed to implement a way to maintain graph state across API calls without keeping it in-memory.
Using a graph execution checkpointer in LangGraph with an external database
This is where LangGraph's checkpointer comes in. LangGraph is able to snapshot graph state at each step through checkpoints, which it then saves in a place that depends on the checkpoint saver implementation you adopt. In this case, instead of using the InMemorySaver, I relied on an SQLite database and used LangGraph's SqliteSaver/AsyncSqliteSaver:
async def stream_ai_tutor_workflow(...): graph_builder = create_tutor_graph_builder() conn = await aiosqlite.connect(settings.data_path / "ai_tutor_state.db") checkpointer = AsyncSqliteSaver(conn) graph = graph_builder.compile(checkpointer=checkpointer)
/backend/src/logic/ai_tutor/graphs/main.py)This way, our graph now references a consistent SQLite database every time it gets initialized (which, as of now, means every time the /chat endpoint is called).
Identifying the same execution across API calls via a thread_id
It's also important that a thread_id is set to identify a single, unique graph execution, which will help LangGraph associate that this second call to graph.astream is a continuation of the first call, and thus resume execution of the same graph accordingly. This thread_id is passed to the frontend as reference for every message sent by the AI assistant, and is given by the frontend as a parameter alongside the user's approval.
In my implementation, I handle thread_id generation in the calling route handler. This considers two possibilities:
- If the frontend doesn't pass a
thread_id, that means this is the beginning of a new graph execution, and the handler needs to generate a new UUID4 thread ID. - On the other hand, if the frontend does pass a
thread_id, that means this is the continuation of an existing execution.
@router.post("/chat") async def chat(request: AITutorChatRequest): ... thread_id = request.thread_id or str(uuid.uuid4()) # thread_id initialized here async def generate_stream(): try: async for result in stream_ai_tutor_workflow( user_message=request.message, thread_id=thread_id, # thread_id passed to the stream_ai_tutor_workflow here ... ): stream_msg = AITutorStreamMessage( type=result["type"], content=result["content"], thread_id=thread_id ) yield f"data: {stream_msg.model_dump_json()}\n\n" except Exception: ... return StreamingResponse( generate_stream(), ... )
/chat endpoint handler initializing the thread_id (/backend/src/v1/routes/ai_tutor.py)In the stream_ai_tutor_workflow function, it's then passed as part of the config used when calling graph.astream to iterate on each node.
config = {"configurable": {"thread_id": thread_id}} async for step_result in graph.astream(graph_input, config): ...
graph.astream with the thread_id (/backend/src/logic/ai_tutor/graphs/main.py)Determining the initial input to the graph based on whether or not you have human-in-the-loop input
The graph_input being passed to graph.astream will also depend on whether or not it's the start of a graph execution or the continuation of an existing one. If it's the former, the system initializes the state. On the other hand, for the latter, a Command is issued to resume execution with some specific data, in this case hitl_input, which is a dictionary passed from the frontend that contains whether or not the user has given their approval in the form of { "content": <decision> }.
if ( hitl_input ): # We assume if there's any kind of human-in-the-loop input, it's a resumption graph_input = Command(resume=hitl_input) else: # Initial state graph_input = TutorState( user_message=user_message, project_id=project_id, conversation_history=conversation_history, highlighted_text=highlighted_text, active_file_content=active_file_content, query_type="", search_query="", found_files=[], file_contents="", pending_note_edit="", output_messages=[], ) ... async for step_result in graph.astream(graph_input, config): ...
/backend/src/logic/ai_tutor/graphs/main.py)Using LangGraph's interrupt function to stop graph execution (within a node) for HITL input
The actual pausing (or more precisely, "interrupting") logic can now be implemented in the "Request Note Editing Consent" node as follows. When the graph execution resumes after the second API call, the corresponding approval or rejection set of output_messages are yielded and processed accordingly by the frontend.
from langgraph.types import interrupt ... async def request_note_edit_consent(state: TutorState) -> TutorState: decision = interrupt( # The key function call for pausing graph execution { "type": "note_consent", "message": f"I've generated the following:\n{state['pending_note_edit']}\n===\nDo you want me to proceed with adding this to your notes?", } ) # The execution resumes here when `graph.astream` receives `Command(resume=hitl_input)` as `graph_input`. # Here, the `decision` variable will hold `hitl_input`. if decision["content"] == "approve": return { "output_messages": [ {"type": "note", "content": state["pending_note_edit"]}, {"type": "final", "content": "Successfully edited note!"}, ], "pending_note_edit": "", } else: return { "output_messages": [ {"type": "final", "content": "Operation cancelled by user."} ], "pending_note_edit": "", }
interrupt function is used and where the graph execution resumes (/backend/src/logic/ai_tutor/nodes/consent/note_consent.py
)In the graph.astream loop, the call to interrupt is handled by looking for the "__interrupt__" property as follows.
async for step_result in graph.astream(graph_input, config): if "__interrupt__" in step_result: interrupt_type = step_result["__interrupt__"][0].value["type"] if interrupt_type == "note_consent": message = step_result["__interrupt__"][0].value["message"] yield {"type": "consent", "content": message} ...
"__interrupt__" property and reading from it (/backend/src/logic/ai_tutor/graphs/main.py)Rendering the consent and note messages in the frontend
To show you what it looks like in the frontend, the consent message type is handled in the following way.
... } else if (data.type === "consent") { // Handle consent request - add to message list and set pending state const consentMessage: Message = { id: `${Date.now()}-${Math.random()}`, type: "consent", content: data.content, timestamp: new Date(), thread_id: data.thread_id, }; setMessages((prev) => [...prev, consentMessage]); setPendingConsent({ message: data.content, thread_id: data.thread_id, }); setIsThinking(false); } else { ...
consent messages (/frontend/src/components/AIAssistant.tsx)
The note message type is then handled simply by adding the text to the currently open note editor.
... if (data.type === "note") { appendToFile(data.content); } else if (data.type === "consent") { ...
note messages (/frontend/src/components/AIAssistant.tsx)Q: Wait, why can't I just treat the user approval as a fresh graph execution instead?
This is definitely possible! Instead of having to maintain an external state through a database, you can just treat the second API call as a fresh execution with some parameter indicating user approval and the note content to be added. In the example I've given for Learn with GenAI, I could've theoretically even just handled the user consent purely in the frontend and just directly edited the note.
However, I think this comes at the cost of potential future headaches when the graph becomes more complex and/or the state you're maintaining grows larger. For example, if there were a lot of nodes that preceded the user approval, and the nodes after the user approval require the information from the numerous state changes that the earlier steps made, you don't want to be stuck passing that state block from backend to frontend and vice versa, bloating your frontend-backend contract with parameters just to allow the continuation of execution of the graph without having to maintain an external database.
Thus, it'll be more of a judgment call based on what you're seeing in terms of volume and complexity of information being passed back and forth between frontend and backend as to whether or not you need state to be preserved externally.
Q: I don't use LangGraph. How do I go about doing this?
If you're working with other agentic frameworks, you'll likely find some kind of human-in-the-loop implementation there too that can be adapted to fit this state snapshotting + execution resumption structure. For example:
- LlamaIndex implements a
HumanResponseEventtype that can be waited for in the tools you implement, then handled when streaming the events while running a workflow given user input. You can have workflow execution happen in two parts by serializing state. - AutoGen facilitates user feedback through both setting a set number of agent turns before asking for human input or having a set of termination conditions. Using this alongside their mechanisms for saving and loading team state or individual agent state would work for a stateless API.
- As of writing, Smolagents has a way of executing its agents one step at a time, allowing for pausing at certain points (where you may want to implement your own termination condition), but you'll have to manage the serialization of the agent's memory yourself. Otherwise, agent memory preservation is currently done in-memory.
Even without existing implementation in the agentic framework you're using, you can implement this if you design your own state snapshotting + execution resumption mechanism. You'll just need the following things (or similar) in place:
- A way to serialize graph/execution state to persistent storage and associating that state with that execution (e.g. via unique execution ID). One possibility would be something like saving to and loading from a
<thread_id>.jsonfile in some cache directory. - A way to terminate agentic execution at designated points, and a way to resume execution through recreation from the loaded graph/execution state, or designing your agent workflow to decide its execution plan differently from the get-go if it receives additional user input, for example. This can be as rudimentary as saving a dictionary-based state and breaking a
whileloop when human-in-the-loop is needed, then initializing a freshstatedictionary to the values loaded from persistent storage + having additional properties to set other execution parameters, like having a"current_node".
Final notes
You can find all the source code used here in the Learn with GenAI repository (permalinked to the latest commit as of writing).
You can also find more examples of how you can use LangGraph for human-in-the-loop in their documentation here. While my current code implementation may not apply perfectly for future versions of LangGraph, I hope this blog post still helps give you an idea of how to use it in a stateless setting.
Lastly, the Learn with GenAI repository is still very much a work-in-progress that I tinker with from time to time, so if you have any suggestions or thoughts about this approval process implementation, please feel free to reach out or even raise a PR!